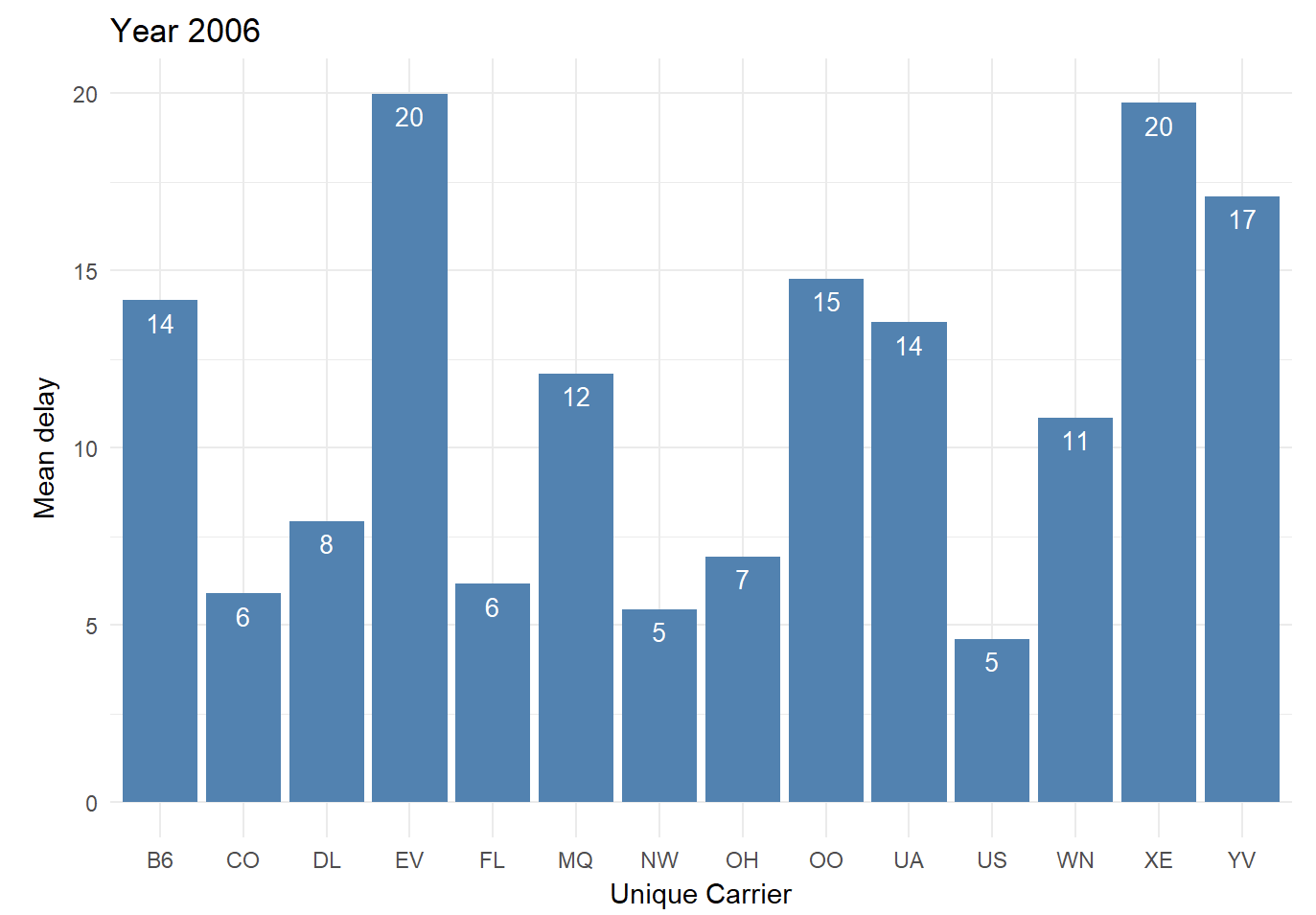
Mean Delay w.r.t Carriers in 2006
As a part of this group project, we worked on 2006 Pittsburgh Airport data collected from Bureau Of Transportation to determine important predictors that could help predict flight delays out of Pittsburgh in today's scenario.
To get to the final prediction, we had to clean up the data to get rid of column's that were unnecessary. We further performed feature engineering on the resulting data to find flights that had delays before arriving to Pittsburgh. Once the feature engineering was completed, exploratory analysis was done in order to detect predictors that could be statistically significant.
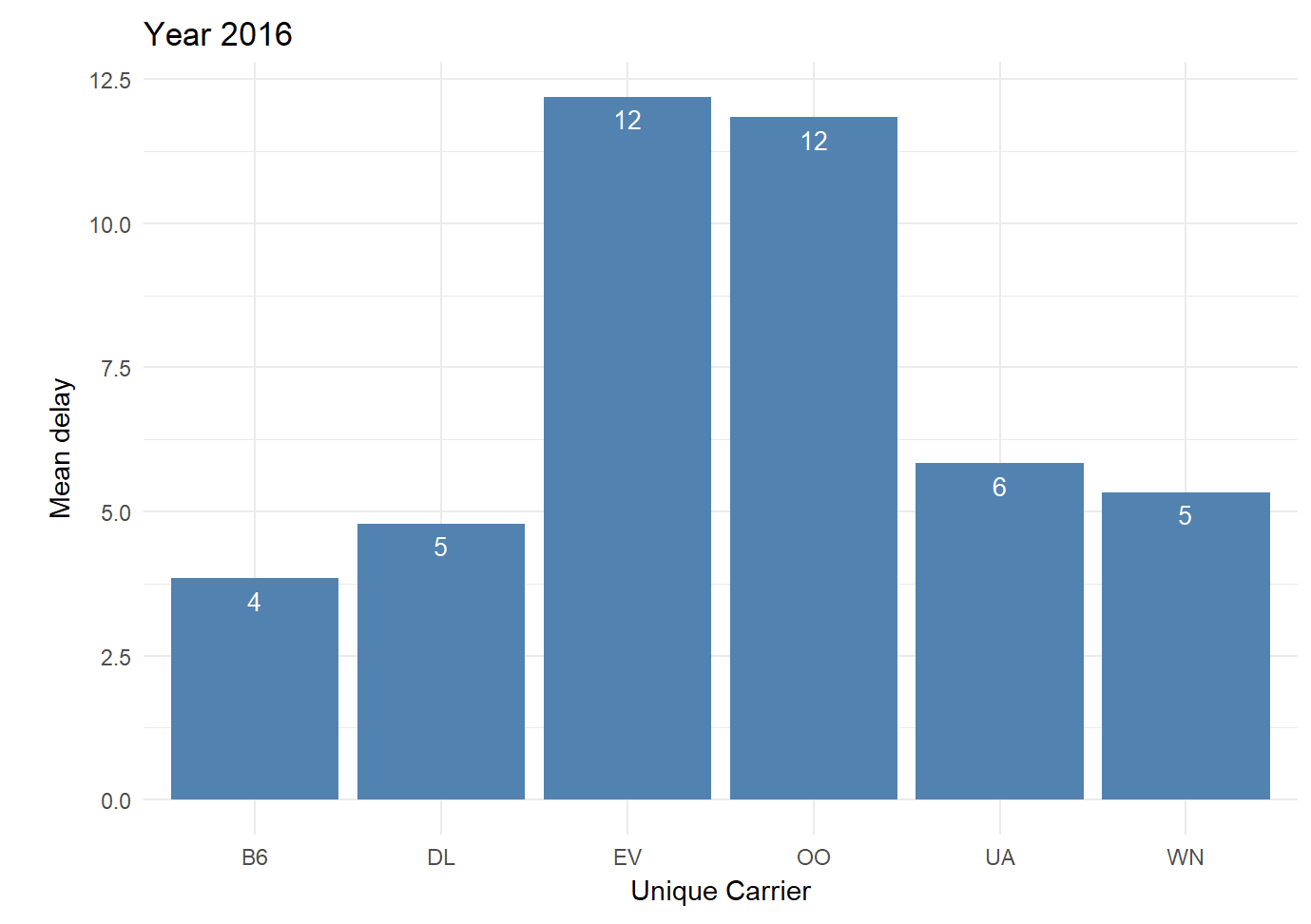
Once possible predictors were decided, we went ahead with modelling. As a part of this project we used three supervised learning modelling techniques including decision trees and random forest. The primary reason behind using multiple models for predicting flight delays was to compare their accuracy. Finally we chose the model that had the highest Area Under Curve (AUC). With the help of the chosen model built using the data from 2006 (train data) we were able to predict delays in 2016 (test data) with more than 85% accuracy.
Finally as a part of our analysis we also provided a classification confusion matrix thereby calculating specificity and sensitivity.