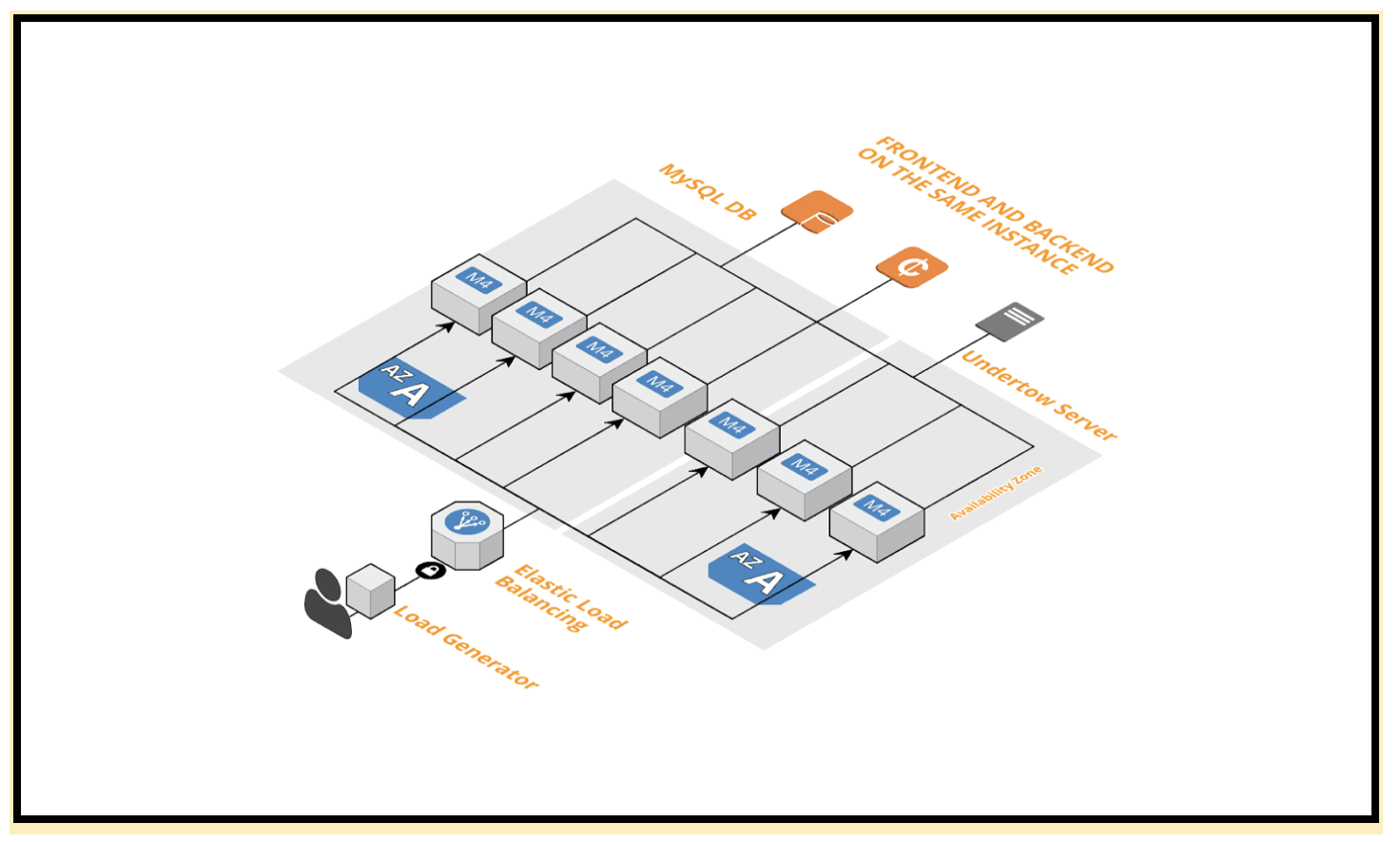
As a part of this coursework group project, we designed a high performing webservice (front-end as well as backend) which handled 1 TB of Twitter source data to cater complicated read and write requests while ensuring optimal throughput.
We designed the database schema in a way most web applications these days design their API's.Since the raw data was huge, we had to perform ETL (Extract, Transform, Load) on the data using batch processing method over hadoop using Map Reduce. Once the data was cleaned and formatted we stored the data in MySQL and HBase using specific data loading processes such as LoadInFile and ImportTSV. We implemented the front-end webservice on a web-framework to cater requests including reads, writes and mixed reads (across databases) while ensuring that the webservice reached a throughput of 10K RPS in a stipulated time.
To ensure target throughput, we implemented various tuning parameters on the front-end including testing different application architectures such as Backend and Front end on the same webserver and having seperate Front-end and Backend servers, implementing cloud watch monitoring metrics such as CPU utilization on instances etc.
Backend tuning parameters for MySQL included optimal and light schema design, indexing, connection pooling, sharding et al. Certain tuning parameters used for HBase included region split, bloom filter, cluster design optimization et al.