Technology boom has exponentially increased the number of online applications. However online marketing has made it harder for the new as well as existing applications to target the right users for capturing the market. While majority illusion can be attributed for the success of latest applications, starting off by targeting influential users has still continued on of the primary marketing strategy. Iterative data processing using Spark is one such methodology that can be used to find influential users in a exponentially increasing social graph of users.
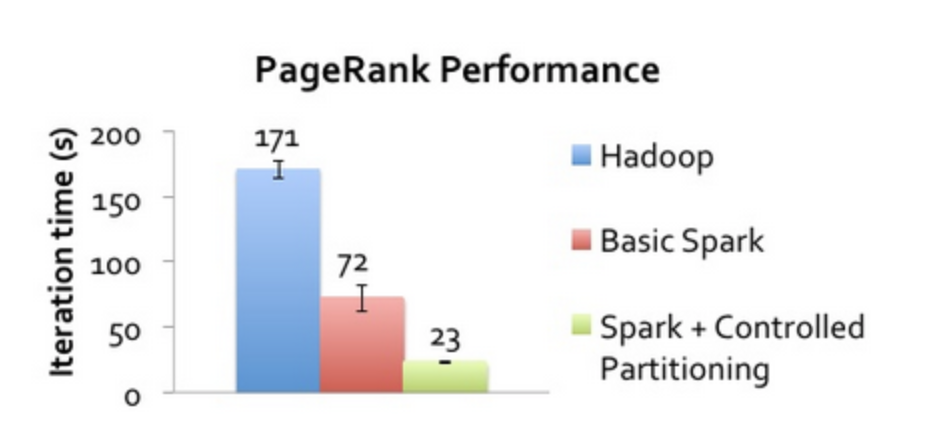
As a part of this project I primarily worked on a 10.4 GB of Twitter Social Graph dataset which contained a twitter user id and the id of the users that they followed. Firstly I used Spark RDD and Spark DataFrames to generate the number of followers of each user and also calculate the number of edges and vertices of the social graph data. Secondly I worked on the implementation of PageRank algorithm to rank each user based on their influence.
After calculating the user influence, I used Spark GraphX library to calculate the second degree influential scores of nodes in the social graph to include nodes that might not be connected with the rest of the nodes in the graph.