Certain studies have shown that millenials are too lazy to enter the complete search text for searching. This has led popular search engines such as Google to implement input text to assist users in framing search queries.
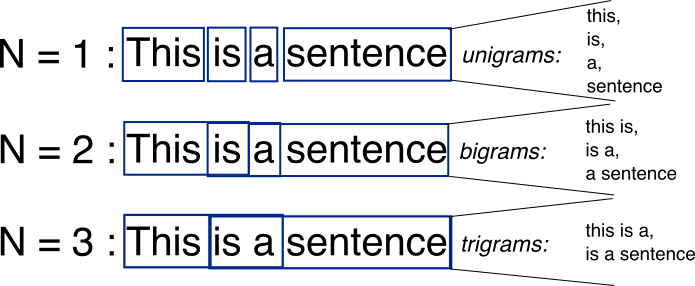
This project was aimed towards the implementation of a similar input text predictor from Wikipedia dataset using Map Reduce batch processing. The input text predictor was based on a language model called N-gram. As can be seen in the diagram below, an N-gram model is used to store probabilities of a word appearing after a phrase, by dividing the phrase into unigram (N = 1), bigrams (N=2), et al. Based on the probabilities and N, words are suggested to the user.
As a part of this project, I parsed XML tags from the wikipedia dataset, cleaned the resulting dataset by removing URL's or similar extraneous data and then passed the data to a map reduce program to generate n-grams for the input text. Once the n-gram model was generated, I used probability calculation to store the conditional probability of every n-gram in HBase. Finally this backend implementation was connected to a PHP front-end to replicate a search engine such as Google. As a part of an additional task, I also implemented a Redis in-memory cache to improve system performance by reducing database calls for every search request.